

















![data quality rules [shutterstock: 2067029825, Dilok Klaisataporn]](https://e3zine.com/wp-content/uploads/2022/07/data-quality-rules-shutterstock_2067029825.jpg)
Because there are so many different rule types and not all is black and white and many rules will have dependencies, using a data quality approach that supports just a single aspect is doomed to fail from the start.
The argumentation for this statement would be the following.
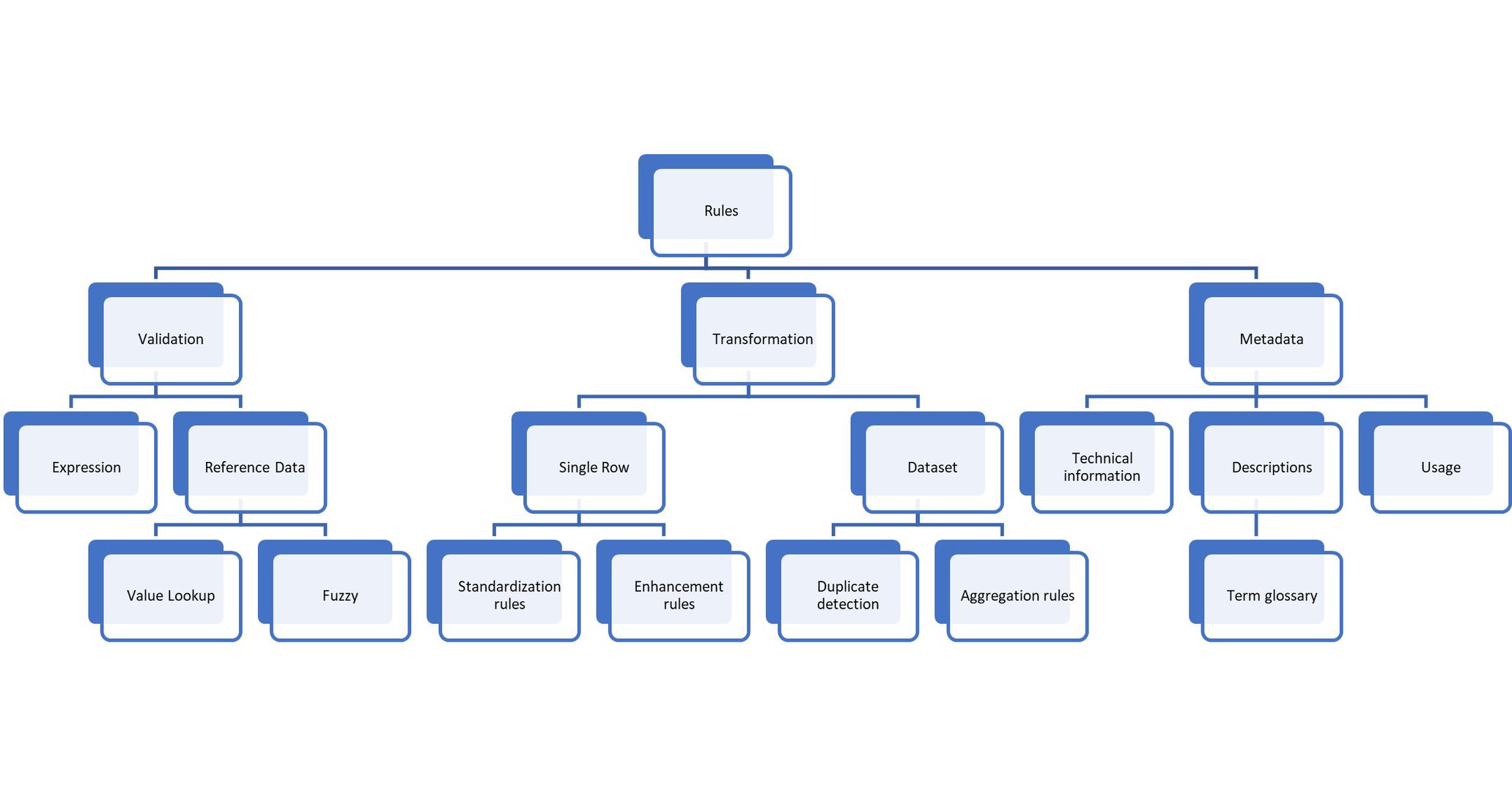
Rule types can be categorized along the following dimensions:
- Rule result. Can be a valid/invalid information, a corrected value, new derived information.
- Data set scope. A rule can only use the current row’s values, combine data with another row, require an entire data set.
- Time of execution. Prior to entry, while transforming, after the load completed.
- Rule dependencies. Are rules based on the output of other rule result?
As usual, the reality is not that simple. Address cleansing is a prime example. The input is an address like “2557 North First Street, CA 95131” and the goal is to validate the address and to correct or transform it. Hence, the result of the rule returns whether the information is valid, the correct value, and any new information (i.e., the city name of San Jose has this zip code).
Rule result
The address cleanse updates multiple fields at once: the post code, city name, street, country. Silently changing the shipping address is dangerous, so feedback must be provided as well. Validation Pass means the address was perfect – complete and consistent. A Warning indicates that some cosmetic changes have been made to the address, but essentially it was correct. And Fail indicates that somebody better has a look at that before shipping the product to this location.
Consequence: The rule must be capable of returning the rule result and change different fields at the same time. Not one field, but multiple fields at once. And the rule execution feedback is a separate kind of information, not just a field.
Data set scope
The typical scenario for data quality rules is that a new record arrives, gets validated, and loaded. But how about the following rule: “A sales order should have 10 cancelled line items or less, otherwise it is an indication of fraud”. This rule must be executed whenever a new line item is added and requires the entire data to evaluate the condition. Obviously, this is a completely different case compared to the single row execution.
- The appearance of a single record triggers the read of an entire dataset compared to only using the values of the received record.
- The rule result is stored at the order level although the rule itself dealt with the line item records.
- The rule execution must be optimized. The engine cannot execute the same test for every new record repeatedly, that would be way too expensive.
The rule types that need an entire data set are aggregation rules (as in the example above), but also deduplication and value lookup rules.
Deduplication is when the record itself is valid, but a similar record exists. The classic example here is master data management. A new entry was made in the product master, but it has the same description, the same name, the same attributes. Having two identical products with different material IDs was very likely a mistake, a second entry for the same customer – things like that.
A rule with value lookups could be one where a sales order requires that the sold-to party exists as customer master record.
Consequence: Rules must fire at a change event, must be capable of reading past and/or other data, and must do so at commit time or with a given latency. A time-based trigger (e.g. every hour run all tests) and executing all tests on all data does not scale.
Where to validate?
Another interesting question is if the rules should be tested at data entry time or after.
Both approaches have their merits. Entering a new material with all its attributes takes ten minutes. Does it really make sense to allow the user to waste that time and later, when loading the data into the data warehouse, raise the duplication error? The business workflow would then be to disable the record and change the created sales order so it uses the correct product number.
On the other hand, forcing perfect data quality at data entry time will make that process way longer up to a point where the system becomes unusable.
There must be a balance between the two approaches and the best solution is to grant the user complete freedom at data entry and make non-intrusive suggestions. The deduplication rule can highlight similar materials and, if the user figures after a few seconds that such a material exists already, they saved ten minutes of typing. They enter an address and get a suggestion of valid, matching addresses and with a single click all fields are filled out.
Consequence: Rules must be reusable in more than one system.
Rule dependencies
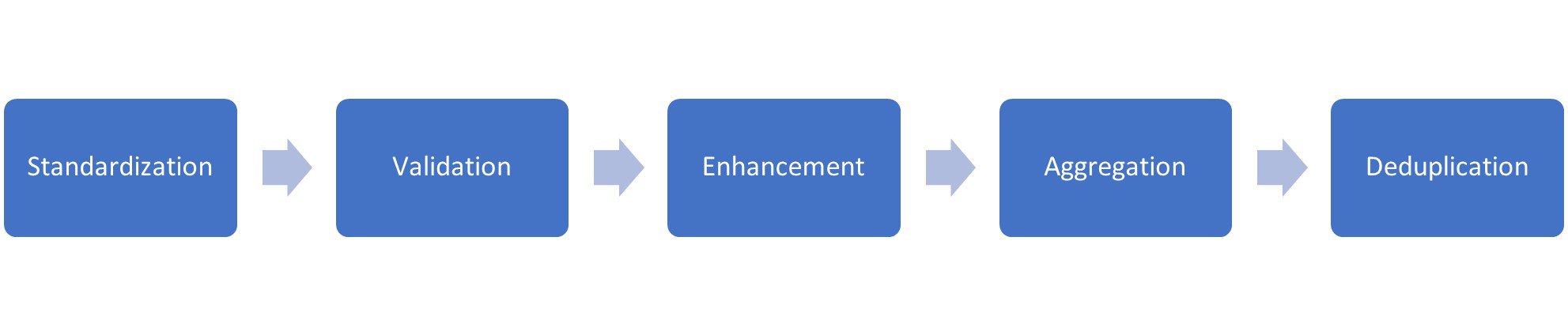
Usually, rules build on each other. First the input data are standardized, e.g., the country has the valid ISO code or a question mark. Now it is much easier to build rules that require the country as input. No more testing if the country is ‘US’, ‘USA’, ‘United States’ or whatever, the standardization rule took care of that.
Same argument for enhancement rules, like what countries belong to what sales region? This rule will be executed after the country standardization, but many specific rules concerning sales regions need that piece of information as their input.
A rule framework that cannot handle rules being applied on the result of other rules is severely compromised in effectiveness.
Furthermore, even within a single rule, there are dependencies. In SAP, the common name for that is decision tables. The idea here is that writing rules that cover all cases can be very difficult, if not done carefully. How about a rule saying: “return X if region is US and revenue > 100; return Y if region is US and revenue < 100; return Z if region is not US”?
From a mathematical point of view, this rule does not cover all cases. Some are obvious (e.g., region is US and revenue is exactly 100), others aren’t:
- Region is null, hence both tests (region is US and region is not US) return false.
- Revenue is negative because it is a return – does the rule still apply?
- One set of tests is using revenue and region, the other just region – is that supported?
A good solution is to apply the test in a customer-defined order and exit as soon as one test found a result. With this model, each test of the rule can be different and edge cases are obvious at entry. Now the entire space of possible values is covered.
Consequence: Simple lookup tables are not enough. Something like decision tables must be supported. Decision tables must allow to use the result from other rules as their input.
Summary
I would highly discourage building a data quality solution with a tool of limited functionality. This is like using a programming language that is not Turing-complete. It simply cannot handle all scenarios, not even via workarounds. If something is missing, it must be open enough to allow extensions. The primary user for any data quality tool will be the business user. Not the data steward, not the data scientist, but the normal business user who knows the realities behind the rules. Any tool not suitable for business users will never get a large set of rules entered and hence will not achieve its goal.
This is the second article in a series! If you would like to read the next one, click here. If you would like to read the first one, click here.

Add Comment