

















![werner daehn data quality rules [shutterstock: 793570558, Blackroom]](https://e3zine.com/wp-content/uploads/2022/08/werner-daehn-data-quality-rules-shutterstock_793570558.jpg)
Equipped with this knowledge, the various data quality tools can be better qualified on what they support, what is missing, and future user requirements.
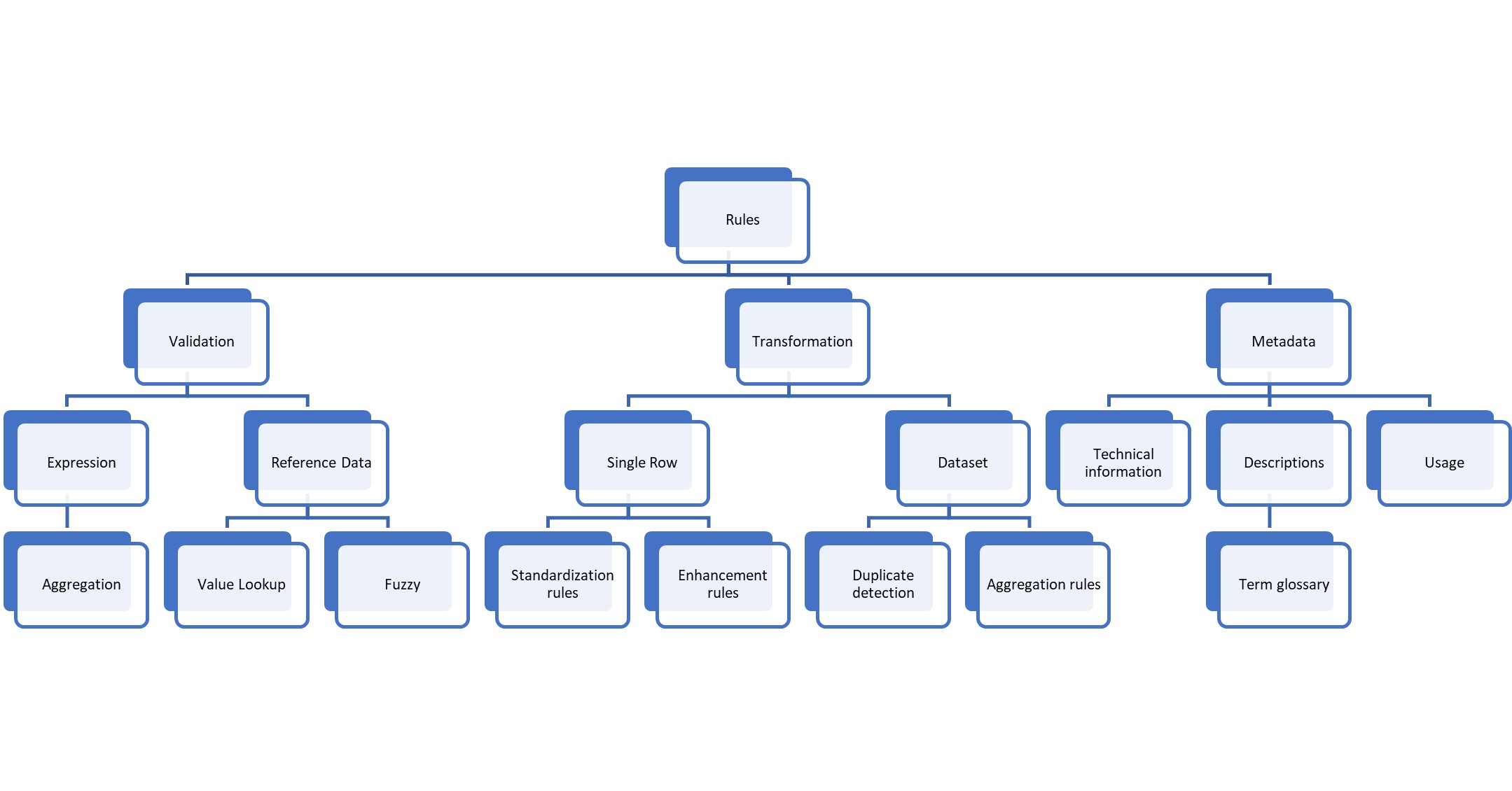
Validation expressions
Validation rules are all those rules that identify problematic rows. The test is either an expression or using reference data of some sort.
Validation expressions work either on individual values, e.g., The field customer name must not be empty. Or they test combinations within the current row, e.g., If the sales channel is online, then the field shipping cost must have a value.
The above examples show rules which are bound to a single column (customer name, shipping cost) but the expression can use information from other fields. For some rules, a binding to a single column looks arbitrary, e.g.. The combination of country = US and shipping type = international is not valid. Both fields are of the same priority, so which field gets the rule violation? It is the combination that is invalid, not one of the two fields. So, it would be better for such cases when a rule is an object of its own and not bound to a field; however, on the other hand, it helps navigating the data.
A special kind of expression is one that combines multiple rows together. An example for such a rule is minimum order value, e.g., No order should be less than 100 USD. There can be multiple scenarios when such a rule must raise alarm. For example: A new sales order with multiple line items is created. All incoming line items are to be collected, and then the rule is applied. The rule calculation cannot fire at each single line item. In the case of a change (either a line item record got added, updated or deleted), the changes have to be applied in the target and then the entire order must be queried to check if the sum is still above the minimum order value.
This makes the entire task quite tricky. Such rules are often executed later, at scheduled times, which is not ideal, obviously.
Validate against reference data
Some validations rules must consider data from other tables. These can be rules that enforce data integrity, e.g., The sold-to party in the sales order must reference an ID that exists in the customer master data.
Another typical example are rules that require well-defined values, e.g., The sales order currency can only be one of the following values. Instead of hardcoding the list of values in a large if-then-else expression, a lookup table is maintained by the rule engine.
More challenging are rules where the referenced record has multiple candidates. An example are reference values with a time aspect, e.g., a valid-from date. For example: An employee has an initial job title, then another job title, and will have a new title starting next month. The rule is: If the current title is Manager, then they must have staff reporting to them.
The extreme case of such rules with multiple candidates is when a rule must consider multiple scenarios and returns a confidence value. Address matching is a prime example of that. An address with city name, street name and house number is fine even without a postal code, as it can be derived. Without a house number it is not so clear any longer – the El Camino Real runs parallel to the 101 from San Francisco to San Jose. In some cities it spans multiple postal codes. If the street name is just El Camino or there are spelling issues, the address can still be validated, assuming the matching logic is more than just a binary lookup. This is called fuzzy matching.
Transformation rules
Another category of rules is when data are created based on other data. One reason is to standardize the input values, e.g., In the input for gender, we may find the entries male, m, Male, M, but all should be standardized to the text male.
Other transformation rules encode business knowledge and add this as new information. For example: Depending on the country of the sold-to customer, the revenue is assigned to either US, EMEA or APAC. Which country belongs to what sales region is defined by the business. This category is called enhancement rules.
The implementation of those rules often uses reference data, just like the validation rules do. Actually, most often, one rule does all at the same time. Address validation checks the incoming data, tries to correct the data, standardizes on the official spelling, and returns a confidence level which controls the validation result of PASS, WARNING, or FAIL.
Another kind of transformation works on an entire dataset instead of single records. Prominent examples are duplicate detection, master data governance, and ‘Golden Record’ creation.
An example here is that we have a customer with the same name, same birth date, living at the same address. This is very likely a duplicate, but how to deal with that? Deleting one record is not possible; for legal reasons most of all, but also because both customer IDs have sales orders associated. The industry standard is to add another customer number – the standardized customer number – as additional field and use that as the actual customer number. The deduplication process creates that number, also with a certain confidence level, for us. A second step could be to create a ‘Golden Record’ out of the multiple records, e.g., one has an email address and the other a phone number, the ‘Golden Record’ should have all available data, and these are stored in yet another table. This process, when augmented with an UI to maintain the ‘Golden Record’ and proper workflows to update the source records, is called master data governance.
Aggregation rules
One of the reasons transformation rules are created is for the reporting use case. The user does not have to filter on all EMEA countries, they can use the sales region field created by an enhancement rule. When it comes to statistical analysis or predictive analysis, categorizing the entire data set is often a requirement, e.g. with building clusters.
All customers should be categorized into low, mid, high revenue. What constitutes a high revenue is unknown, the only rule is that at the end, the sum of revenue for each of the three buckets should be about the same. This requires reading the entire dataset and to use a k-means algorithm to build equal-sized clusters and assign each customer the information what bucket they belong to.
This will certainly be very valuable information when analyzing the data. Additionally, the BI users will be spared running this complex logic at query time.
Metadata
A completely different kind of rules concerns data about the data. A few thoughts of what would be helpful:
- When executing a query, wouldn’t it make sense to know how current the data are? Otherwise, two people query the revenue, and in the meeting, all that is discussed will be why the numbers are different.
- What constitutes a low, mid, high revenue customer? What are the cluster limits found by the k-means algorithm?
- What does the data model look like, what constraints are enforced?
- Where do the data come from and where are they used? This would help the users to understand that the revenue column contains values from multiple source systems and hence differs from the revenue number shown when comparing with just one system.
- When was a row added? Helpful if, for example, it seems that data about customer revenue cannot be found in the source system, and we need to find out why.
- What rules have been applied to the record? Maybe the rule was added recently and the record in question was loaded earlier? Maybe a rule has not been applied because another had a higher priority?
A proper data quality solution must include such metadata as well to provide maximum value for the end users. Having said that, the business intelligence tool capabilities must be considered for some of those requirements as well.
Another helpful point is textual information. What is revenue? Gross or net revenue? Does it include employee discounts? Is it the order entry or the billed number? Does it honor the revenue recognition rules? Even if all this information would be present in mathematical form, it is hard to understand. Defining what each key performance indicator is in detail will help increase trust in the numbers. Just imagine if the reporting and the SAP system would show different numbers: Without the knowledge that the definition of the two values is different, the user wouldn’t know what to compare.
This is the third article in a series! If you would like to read the fourth and last one, click here.


Add Comment