

















![data quality rules sap [shutterstock: 207667846, Michal Chmurski]](https://e3zine.com/wp-content/uploads/2022/06/data-quality-rules-sap-shutterstock_207667846.jpg)
Business Rules Framework (BRF+), Hana Rule Framework, SAP Information Steward, SAP Data Quality Services, SAP Data Services (Data Quality), and many more – the overlap between those products is smaller than the term data quality would suggest, because each focuses only on one sub area.
One way to categorize data quality rules is by their required capabilities: validation, transformation and metadata.
- Validation rules are rules that return PASSED or FAILED (or WARNING). A typical example is to check for allowed values: GENDER shall be either m, f, d or ?. All other values do not pass the rule and must be corrected.
- Transformation rules change the value. Here, the rule would be GENDER of m or M means male, female is similar, and <blank>, ., X, and all other cases change the value to ?.
- Metadata rules are more of a descriptive nature. They convey knowledge. Example: When calculating the revenue per GENDER, use the gender of the sold-to party, not the bill-to party.
I have seen multiple data quality products that treat validation rules and transformation rules as the same thing. In fact, the majority of them do. One returns the information PASS and the other returns a value for GENDER – so what is the issue with interchanging them?
Validation rules are different
The first difference is that a transformation rule modifies an existing column, whereas a validation rule creates new information. No problem – transformations often add new columns too, e.g., GENDER_CLEANSED next to the GENDER column with the original value.
If we treat validation rules this way, the result would be many additional columns, one for each validation rule. GENDER_VALIDATION_RESULT, NAME_NOT_NULL_RESULT, … If there are 100 rules to be applied, 100 additional columns are required. Worse, what we actually want to know is if the record as a whole did pass the data quality threshold. In other words, one column with the aggregated information of all rules. This can be done in a single expression; however, then the rule definition for this one column would have all the 100 tests in one huge formula, and the information on which rule was violated would be lost.
Hence, native support for validation rules is important and the result must be:
- Which rules have been executed?
- What was each of their result?
- What is the aggregated result of all tests applied to a row? (PASS+PASS=PASS; FAIL+<any>=FAIL; PASS+WARNING=WARNING)
In the following screenshot, the SalesOrder object with OrderNumber, SoldTo, OrderStatus and all the other columns gets one additional column called __audit. It contains the overall validation result plus an array of all executed rules and their result.
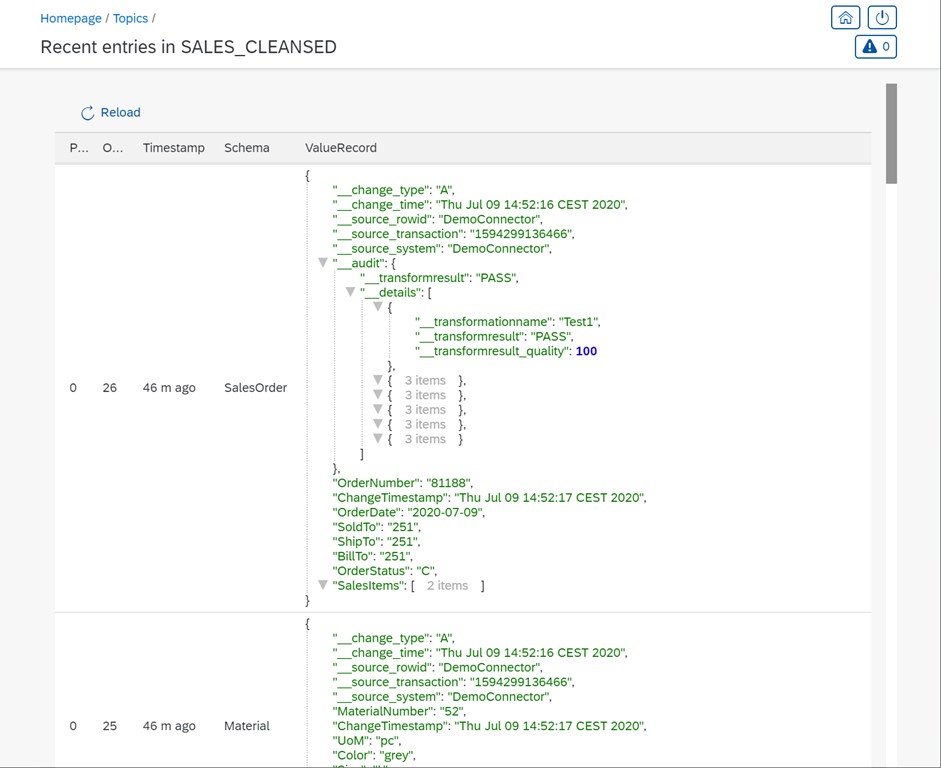
SAP Information Steward was designed with this in mind but struggles with producing the rule details. Its assumption is: If a product is built according to the above requirements, the amount of data produced would be too huge for any database. Just imagine the system gets one million order lines per day, each record is tested against 100 rules. That would result in 100 million records of which rule has been executed and what the rule result was!
Yes, it is too much data for a database, but we now have big data technologies that can handle these volumes easily and at low costs. So instead, Information Steward holds only the aggregated data. How often rule #1 was violated in the current run is all the user knows.
The other design flaw of Information Steward is that it cannot (really) be integrated with the ETL flow. Per its design, all data are tested at every run. All the billions of order lines are tested, the rule results counted and then we know that yesterday, 0.111 percent of the rows had a problem and today it is 0.112 percent in total.
The question of why suddenly 50 percent of today’s orders are considered invalid it cannot answer.
If the complete row plus the rule results are stored, a simple query would show that all rows of one distribution channel failed today.
Note: Sample data can be produced in Information Steward.
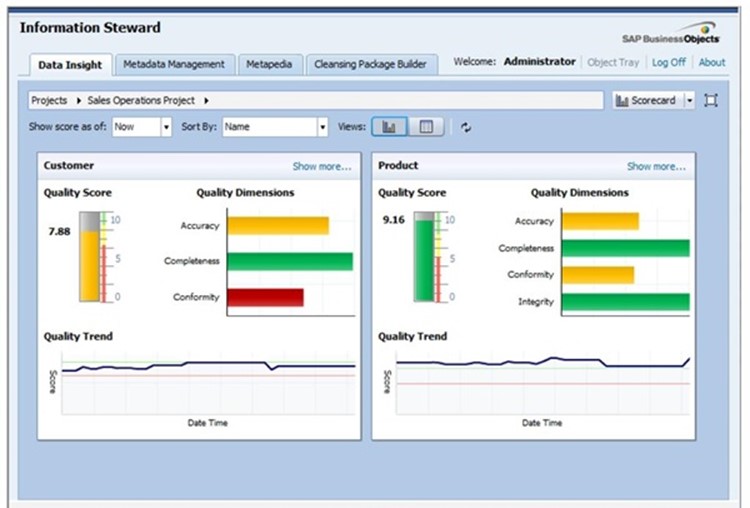
With a big data architecture, the amount of data is no problem. The data warehouse still only gets the aggregated data while the data lake (based on big data technologies) holds all the details.
I would recommend Apache Kafka as the real-time stream of changes (new order lines, for example) and one consumer of the data is the rules service. This service takes each input row, applies all tests, and adds an array of all test results plus an aggregated rule result field to the individual row itself (the audit structure). The validated data goes into another Kafka topic (see screenshot above). Data consumers can now decide which data to pick or store for easy consumption for their application users.
Another approach is to combine validation and transformation into one feature, as SAP Data Services does in the validation transform. It provides one place to define the rules, e.g., GENDER must be one of m, f, d, ? and if it is not, then replace the value with ?. The validation transform keeps track on how often the rule was violated, if a rule violation is considered as FAIL or WARNING, and it allows to change the value for increased data quality.
Metadata rules
The third category of rules is about metadata and summarizes all rules that go beyond values. Many of these rules are enforced by the database.
- A customer identifier must be unique (primary key constraint).
- An address field must not be empty (not null constraint).
- A sales order has a sold-to party and the value must exist in the customer master table (foreign key constraint).
This is important knowledge for consumers and hence should be available. Especially SAP is infamous for providing this kind of information and still the data violate the rules. For example, one cost center belongs for a given period to a single parent node, meaning the primary key consists of node and period, and yet, there are multiple nodes with the same key in one period.
Another kind of metadata rule is the business term glossary. The system provides the net revenue. All clear now, right? Ask ten different people, you’ll get ten different definitions of net revenue. Order entry amount. Invoiced orders. GAAP revenue recognition. Including or excluding employee discounts. A place to enter this information is trivial, yet only few products allow for that.
Types of rules
Each of these three categories can be further refined. One important thing to be aware of: Each of the data quality tools support only a very narrow set of functionalities.
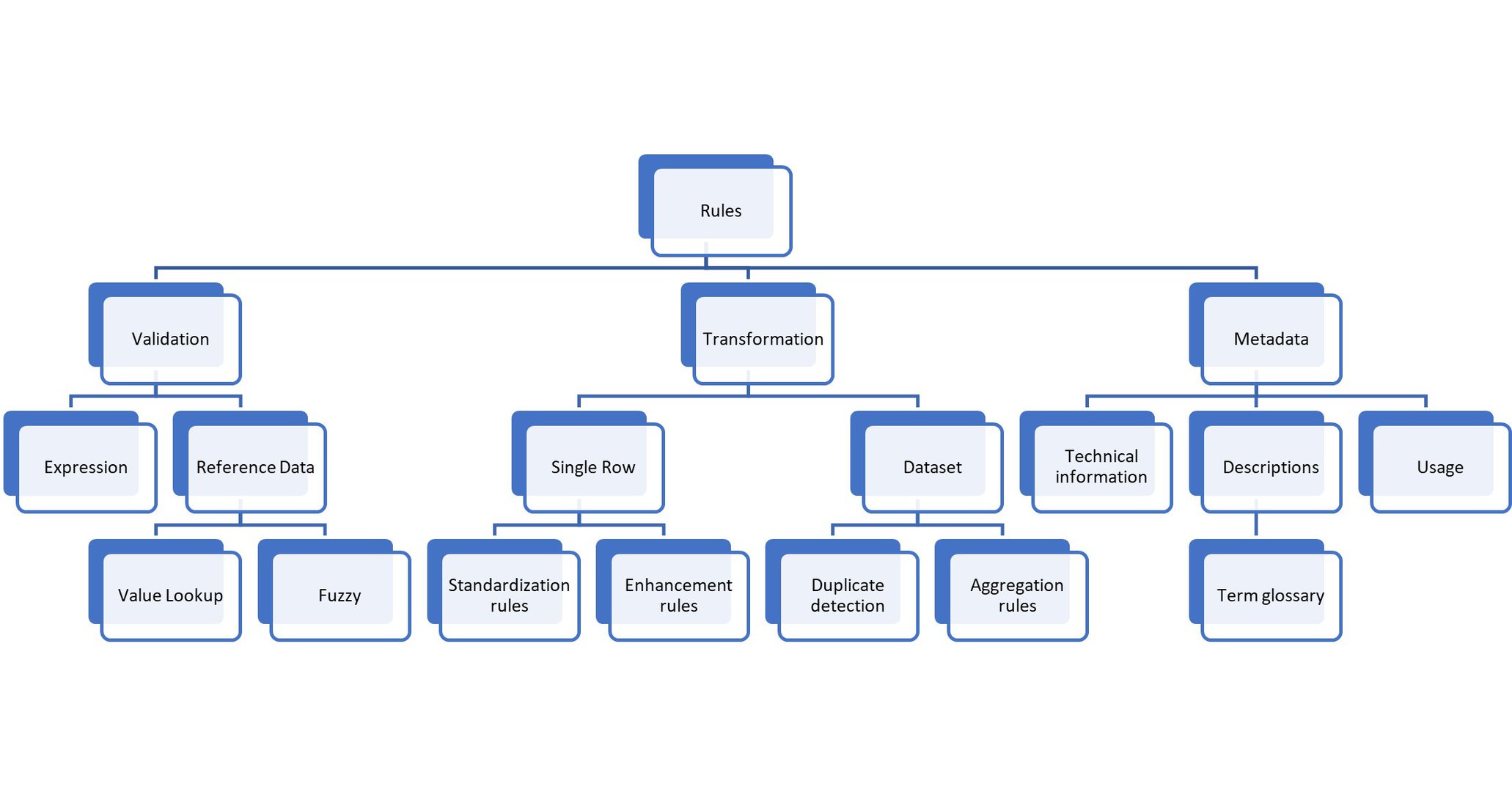
The Hana Rule Framework is only about expression validation. SAP Data Services supports the complete validation and transformation area but distributed across features. SAP BRF+ Decision Trees are about enhancement rules. SAP Data Quality Services supports fuzzy validation of address data and nothing else. Information Steward does metadata and validation.
No end user expects that, obviously.
If you can’t buy it, build it
A tool that covers all of the topic data quality would be ideal, but that is far from reality. Using different tools for different areas breaks integration, hence it is not a good option, either. And because SAP builds these solutions per use case, tools keep popping up while others are discontinued. The situation is only gradually better with other software vendors. Which puts the burden of building a useful data quality system for each project onto us. This shouldn’t be a problem if we pick the right tools: Confluence wikis for the business term glossary, an open data integration tool with validation and transformation features, SQL scripts for aggregation rules… something along those lines.
This is the first article in a series! If you would like to read the second one, click here.

Add Comment