

















![sap data services 360eyes [shutterstock: 2003398163, VideoFlow]](https://e3zine.com/wp-content/uploads/2022/03/sap-data-services-360eyes-shutterstock_2003398163.jpg)
A data integration project requires hundreds of dataflows with complex business logic. It is easy to forget something. Data Services just got an update – albeit not by SAP itself, but by SAP partner Wiiisdom – and now has the required features to increase the project resilience.

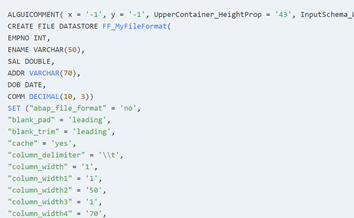
When I was product manager for Data Services, we added some basic functionality in that regard, but not as much as I had always hoped. The main issue is that getting the data is tougher than it looks, because the majority are stored as text in the repository in the so-called ATL format.
Example: The ATL description for a flat file looks like this and is stored as a free form text in a database table. Finding all files with a certain setting requires to interpret the text.
Recently I learned that there is a product called 360Eyes for Data Services which does what I had always envisioned for Data Services and more.
360Eyes reads the repository, parses the ATL language, and stores the extracted data in database tables ready to be consumed. This has multiple advantages:
- The data can be queried and visualized with any reporting tool, including SAP BI tools.
- All kinds of sanity checks can be built using the reporting tool.
- Because the data is never overwritten, comparisons can be made to figure out what changed.
- Regulatory business requirements can be validated as another type of check.
As I can attest from my own customer projects, this boosts the quality of Data Services projects, increasing the developer efficiency and the quality of the data integration data flows.
Another way to look at it is using it as part of the Unit and Integration tests which are common in professional software development. To get an idea about savings, here are a few examples from past projects I was involved in.
User story: Initial load
A go-live is a stressful project phase, in a data integration project even more so because the first task is to perform the initial load, for example taking the entire SAP material master data with millions of rows, converting each to the target data model, and loading them into the target system.
In this specific user case, it had been tested over and over again, and it had to happen during one single weekend. And it did, with a few minor hiccups. Monday morning, people complained that some materials existed twice for an unknown reason. Further analysis showed that all dataflows related to an initial load truncated the target – except one. There, the flag had been forgotten.
The sanity check “Select all dataflows with the name DF_*_INITIAL where the table loader is not set to truncate-table” would have uncovered that issue. However, there is no such functionality in Data Services. Checking these settings manually takes a long time. The 360Eyes database contains that information readily. One query is all it takes, and we can immediately identify the problematic data flows.
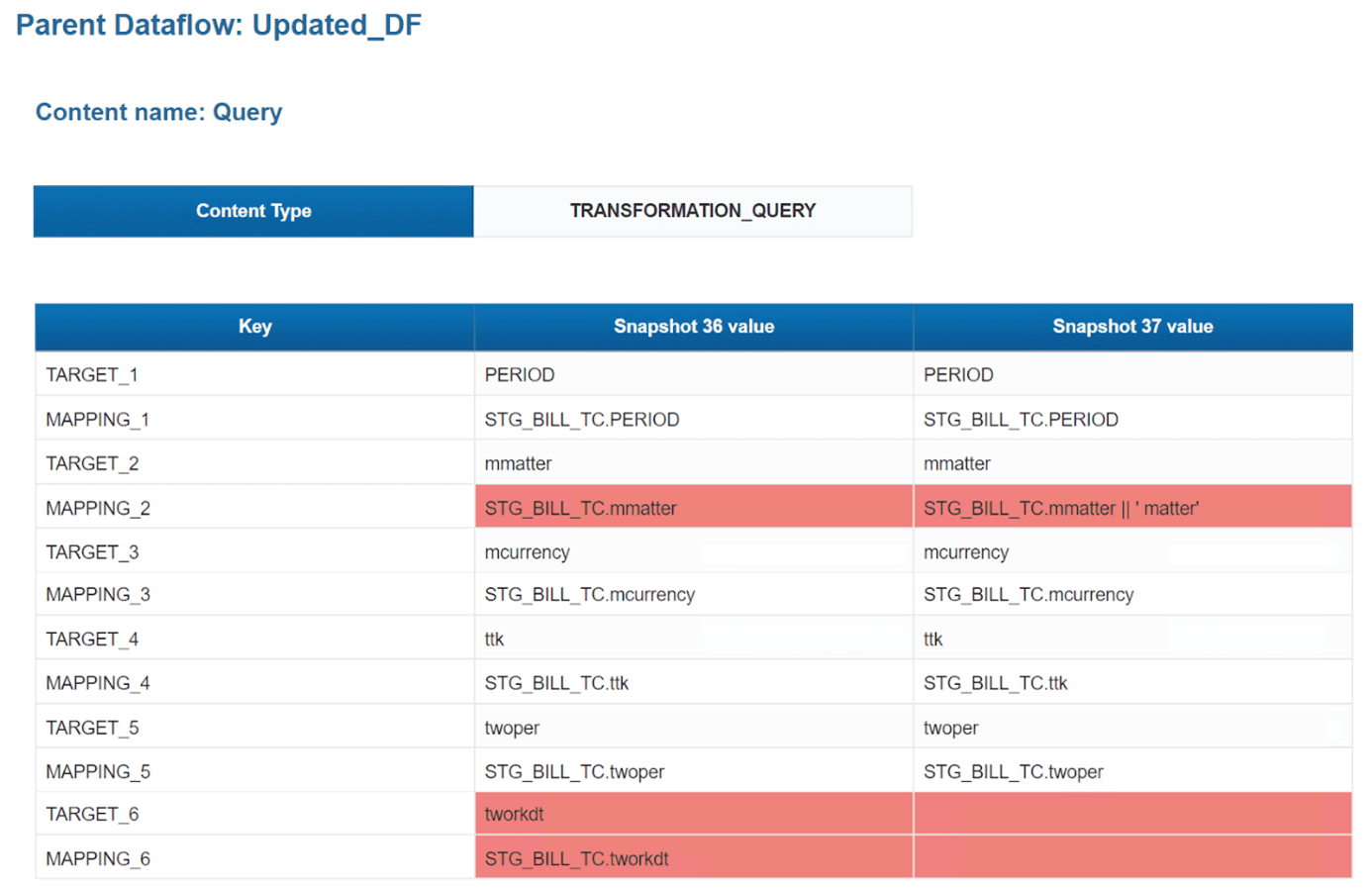
User story: Version control
Not all Data Services implementations use the versioning functionality provided by central repositories and check-out/check-in processes. This is particularly true in development environments, where changes are frequent. The dataflow comparison functionality allows users to quickly compare two different versions and see what has changed.
User story: Performance reduction
Once I got a call from an IT department. They said that the delta load job took too long, so much so that it was impacting other SAP ERP tasks scheduled at the same time. The delta load used to take one hour when it was developed, now it ran for three hours! We decided on a chart visualizing the delta-run times for every single day to uncover the root cause.
We were primarily focusing on three questions:
- Did it happen just by accident, for example because of a slow database?
- Did the delta load get slower gradually because the data volume increased?
- Was there a particular day the run time jumped from one hour to three hours?
Thanks to the data made available in the 360Eyes database, such a chart can be created easily.
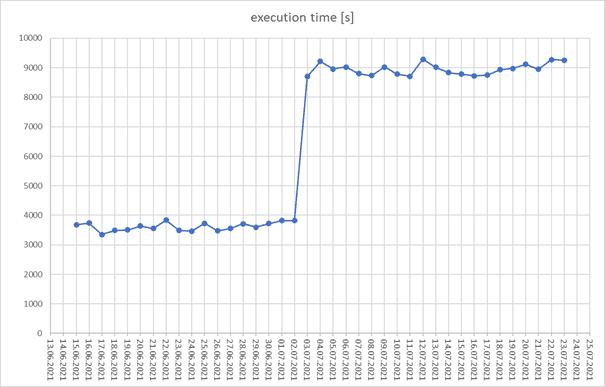
It clearly shows that something changed on one particular day. With this information, the 360Eyes database can be queried to find out what code change was made.
Had I only used Data Services, I would have needed to compare the runtimes manually for every single job execution, write down the execution times of each dataflow before and after, and then investigate the dataflow details.
Summary
These are just some examples showing the potential of opening up the SAP Data Services internal data. I actually find the approach quite clever. While SAP did incorporate visualizations into the SAP Data Services management dashboard, which might or might not suite customer needs, 360Eyes’ approach is to make the data available in a regular database.
As such, users can either utilize the provided reports or build additional visualizations based on their requirements. They are no longer limited to the prebuilt visualizations but can instead harness the full power of the BI tools already used in-house.
The available data range from the individual Data Services objects and their settings to operational statistics and impact/lineage info – all of that with the complete history to answer questions like “What changed?” or “Is there a trend?”. I am looking forward to see what else customers will come up with now that the data are finally available.


Add Comment